Navigating the Rising Tide of Stealth Cyber Threats: A 2024 Perspective
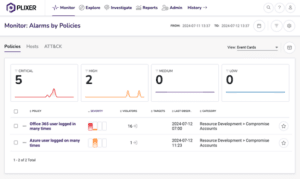
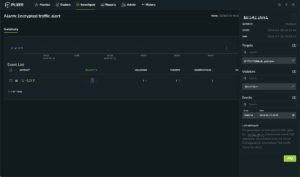
As we navigate through 2024, the cybersecurity landscape is increasingly dominated by stealth and sophistication. The recent CrowdStrike Global Threat Report highlights a dramatic rise in covert activities, including data theft, cloud breaches, and malware-free attacks. This trend ...
Continue Reading