
With the onslaught of malware and cloud applications increasing, network traffic intelligence has become increasingly important. When an infection is unearthed and the incident response team moves in to figure out what exactly has happened, one of the first things they will do is request the logs, including the flow (NetFlow and IPFIX) data. Network and application issues are troubleshot in a similar way.
Investigation requires access to some type of history, else you have to wait for the issue to pop up again. Who wants to wait for the malware to exfiltrate even more confidential information? That is where today’s Network Detection and Response systems come into play. The problem is that gathering this data for the NDR in traditional ways, like packet capture, is resource-intensive and just not scalable. On the flip side, an issue with collecting flow data alone is that it can often lack the contextual details that shorten the investigation. So what is the best approach?
Security intelligence
On the security side, context can mean the username associated with the IP address, or it can include the fully qualified domain names reaching out, or the URLs being visited. These logs can sometimes be found in IPFIX exports, but usually have to be collected from Microsoft Active Directory, Cisco ISE, Forescout CounterACT, RADIUS, or the DNS. Once ingested, these details need to be cross-referenced with the IP addresses found in flow data in order to be useful. Once available, this additional context in a single Network Traffic Intelligence system allows security professionals to shorten the MTTK (Mean Time To Know).
Application intelligence
On the application side, context can certainly include the same details sought by the security team, but may also include details on round trip time, retransmitted packets, layer 7 application information, URL visited, TCP window size, VoIP caller ID, jitter, packet loss, codec, session duration, HTTP error codes, and much more. In fact, network administrators often have to choose which details they want to export from their routers, firewalls, switches, servers, and probes, else the size of the flows becomes too large. This leads to excessive amounts of flow data on the network, causing further congestion.
As a result, richer contextual details are sometimes temporarily exported until the problem becomes apparent and then the extra information can be turned off. The culture surrounding application issues tends to blame the network until they can prove otherwise. Certainly MTTK applies; however, in networking, sometimes we call it MTTI (Mean Time To Innocence).
History is imperative
Although the amount of flow history available doesn’t always matter on the application side, on the security side it is imperative. Often, 30 – 90 days is not enough when trying to ascertain when the infection first penetrated the network six months prior.
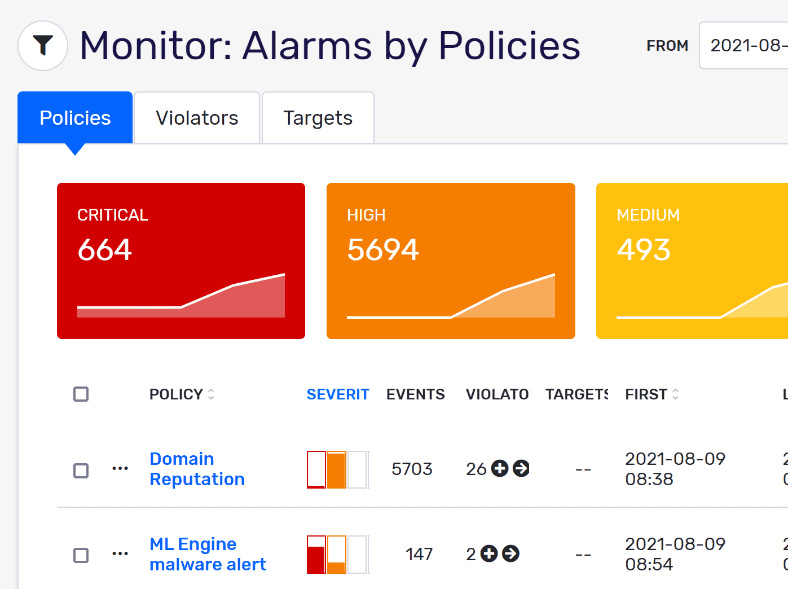
… malware can reside undetected in health information systems for weeks, months, and even years.
Jarrett Kolthoff, Former Special Agent with U.S. Army Counterintelligence
Not having all the data prevents security teams from being able to tell the complete story, from initial infiltration to clean-up. Network traffic intelligence systems should be able to archive the data for as long as the business deems necessary.
Billions of data points in seconds
Large enterprises and service providers generate big data, which means they require a data collection platform that can turn conversation data into actionable, real-time intelligence at scale. The best solutions allow customers to choose from cloud-hosted SaaS offerings, which promise massive ingestion rates and allow the vendor to provide the ongoing maintenance. Other times, the cost of maintaining data in the cloud is too pricey, so it makes more sense to invest in an on-premise solution where data can sometimes be archived more inexpensively.
No matter what deployment method your environment requires, companies are finding that leveraging flow metadata, like NetFlow and IPFIX, not only requires less resources, but is scalable and ultimately far more cost-effective. When looking for a solution, ask yourself whether the solution provides a fast reporting engine with rich context and ongoing monitoring of suspicious activity like DDoS attacks. Does it detect other types of unwanted behavior patterns via technology like machine learning? Does it communicate with the other tools in your NOC or SOC environment? Throughout day-to-day operations, ad-hoc analytics are required by both security teams and application managers in order to improve operations, optimize capacity and resolve anomalies fast.
We all know it: the world as we know it has changed and will continue to do so. What I want you to consider is how will your company deal with these changes? As I mentioned before, employing enhanced metadata will immediately help you expand your visibility and collect that data in a realistic and scalable way. Don’t believe me? If you’re looking for an NDR solution that provides rich conversation visibility along with providing the flexibility to integrate that data into your current environment, why not evaluate Scrutinizer?
Related
How Network Data Allows You To Detect DNS Attacks Like The “Decoy Dog” Exploit
In today’s complex cybersecurity landscape, the battle between hackers and defenders is a continuous chess match. Recent revelations about the “Decoy Dog” exploit have
::
