
Although the concepts of artificial intelligence and machine learning are not new, they have recently garnered mainstream attention. As is normal in the technology space, the initial hype makes it sound like a panacea and cybersecurity vendors are scrambling to hitch their marketing messages to it. This blog will help you differentiate fact from folly and arm you with specific questions you can ask vendors as you evaluate new solutions and navigate the landscape of all things cyber.
What Is Machine Learning?
To start, let’s take a look at the history of machine learning. From an academic perspective, the concept has been around a long time (literally decades). But it wasn’t until around 2006 that deep learning algorithm breakthroughs happened, which gave us the opportunity to ramp up our machine learning efforts more aggressively. In machine learning, speed and effectiveness are related to computational power. Thus as the growth of the public cloud has rapidly increased, so too has the speed and effectiveness of machine learning.
Machine learning, as a term, was coined in 1959 by Arthur Samuel. At its roots, it’s a statistical technique that allows for learning without programming. Learning is predictive rather than relying on “if this, then that” programming models.
Furthermore, with traditional programming, people write code to create a program. That program establishes the rules for how a computer uses input data to define a specific output. The idea of machine learning flips this model on its head. Instead of defining an outcome, machine learning looks at the outcome and then creates a program intended to define what normal input is.
There are two types of machine learning that I’d like to address here: supervised and unsupervised learning.
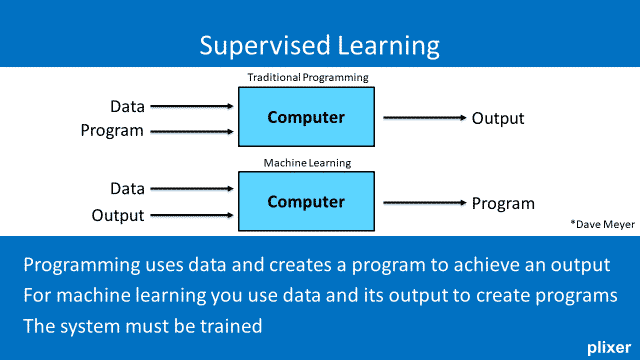
Supervised Learning
In supervised learning, you take the data and its output to create programs. In this model, the system must be trained. This requires human input to define labels that represent what is a normal state, or normal data. The input data, provided by humans, is manually associated with the desired output. As such, the human is defining the normal state, and the more data you feed the system, the greater accuracy you have.
Unsupervised Learning
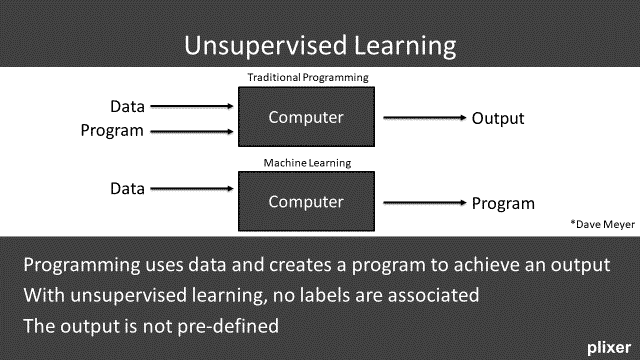
The other mode is unsupervised learning. This is the type of machine learning that the market is really looking for. In this mode, you remove the human element because you no longer need a person to model the output. Input data is fed into the system, and the system looks for patterns and defines the program dynamically. In this case, there are no labels associated and the output is not predefined.
So, now that we understand what machine learning is, let’s take a look at its counterpart, artificial intelligence.
What is Artificial Intelligence?
First, artificial intelligence and machine learning are not synonymous terms. Machine learning is a fundamental building block of artificial intelligence. This means that you require machine learning in order to have artificial intelligence. With artificial intelligence, the environment is perceived rather than programmed and the goal is to achieve problem-solving, not just learning.
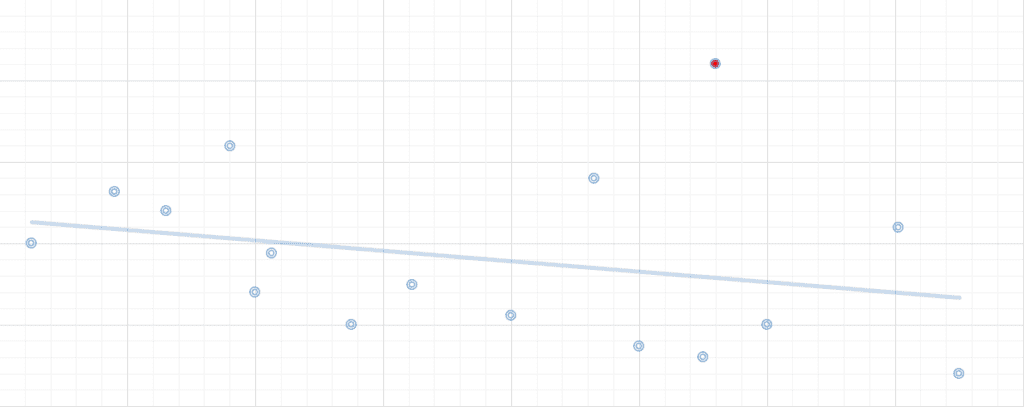
The figure below represents a scattergraph of data points from a machine learning algorithm. When data points fall within what is considered a normal range, all is good. But when machine learning identifies an outlier (the red dot), it will flag this outlier with an alarm. The value that artificial intelligence brings is to problem-solve whether that outlier data point can be easily explained, or if it is actually a problem. Artificial intelligence goes beyond learning and takes us further to problem-solving.
The reason it’s important to point out these differences between machine learning and artificial intelligence is that many vendors in the market are merging these terms together or using them interchangeably. But each plays a different role, and the maturity of artificial intelligence within certain segments lags behind.
The Hype Versus The Reality
The hype
Gartner publishes a hype cycle that plots the maturity and market expectations of various technologies and for many different market segments. This hype cycle walks through an innovation trigger, where something happens in the market that drives a need, and a new technology comes along. Over the years, the expectation of what that technology will do rises up the slope the to a point called the “peak of inflated expectations.” We are arguably at the height of that peak as it pertains to machine learning and artificial intelligence. We are at a point where many seem to believe that machine learning and artificial intelligence will remove the human element from cybersecurity entirely, where software will take over the function of risk and staff will no longer be involved in threat detection.
Certainly these technologies will over time assist us in seeing hidden patterns people would miss and finding problems that the human brain can’t conceive of, but currently, there’s a gap between expectations and reality. Over the next several months or years, as the technology begins to fall into the trough of disillusionment, expectations will be adjusted.
The reality
The current reality for achieving good value from machine learning and artificial intelligence is that you must be able to identify a strong baseline of the data structure. If you’re going to evaluate input data and make some associations between the input data and what is perceived as normal, you require a strong baseline. There are some use cases that have gained traction and I’d like to share three of them.
Facial Recognition
With today’s high-resolution imagery, it is very easy to baseline facial features. Deviations in weight gain or facial expressions can also be modeled to assist in good baseline definition. Current use cases include crowd recognition and authentication applications. As an example, recently released smartphones can log in to a device using the face of the user.
Image Identification
Google, as an example, has mapped images of nearly every street in the world. Because of its Street View capabilities, a separately taken image can be correlated to Google’s database to determine where in the world a picture was taken. This technology can also be used in medical applications to help medical professionals detect anomalies in medical scans, e.g. MRI, PET, CAT.
Natural Language Processing
Think Siri and Alexa. This type of technology is prevalent in today’s world. Today more than ever, users are using natural language to ask questions or to have their device perform tasks for them. Specifically, because language is finite (there are a set number of words in a language’s vocabulary), applications can be programmed to perform a large number tasks and to respond to almost any task available on the device. As with facial recognition, deviations in speech and dialect can be modeled to represent the data accurately.
Networks are Snowflakes
Unlike these use cases, networks are snowflakes. Each network is different from the next. The environments are unique and ever-changing. Solutions must perform unsupervised training once they are deployed, meaning that the product itself must be able to understand these patterns, recognize what’s happening on the network, and attempt to create a baseline.
The problem here is that baselines are moving targets. It isn’t uncommon to have new devices added to the network daily, or new applications installed. Even with old software, new patches must be regularly installed, or users may upgrade their operating system. Any of these changes can very easily become a deviation to a baseline. How do the platform and product differentiate between what is a problem to identify as an outlier to normal behavior versus what is a normal, everyday change?
With that in mind, networks and network traffic are very difficult to apply machine learning to. But what can be done?
Narrow The Scope to Achieve Short-Term Value
What I believe is valuable—and where you can gain real-world traction today—is when you don’t take that broad brush approach at trying to look at everything. Instead, you actually narrow the scope of the traffic and the data that you have.
When you narrow the scope of where you apply machine learning, you can focus on the behavior of specific protocols and applications because these they’re well-known. You should ask yourself, “what is important to the business?” What important applications can you baseline and report on deviations?
To help you understand what I’m talking about, let’s look at some real-world applications that we can apply artificial intelligence to.
DNS Data Exfiltration
This is a fairly difficult problem to solve because you’re essentially hijacking a valid protocol in order to get data out from a network. In DNS exfiltration, you can stuff data into a DNS request. As an example, you could send data to the authoritative DNS server by making a DNS query similar to 0800fc577294c34e0b28ad2839435945.other-random-hash.example.com.
In this case, data is sent out via DNS, but there are no responses. Machine learning is very applicable because it can look at DNS traffic and understand when traffic is sent to an authoritative server but doesn’t receive a valid response.
Credential Misuse
Phishing attacks are prevalent, and they are very successfully stealing valid user credentials for the people that are on your network. The problem this creates is that hackers who are trying to gain access to resources on your network are no longer trying to brute force their way into it. They have the key, and they’re going to make a single attempt to log into a server. If it doesn’t work, they’ll move on.
Again, machine learning is very useful here because your users have a set number of servers they connect to or access on a day-to-day basis. It’s easy to see when a credential is tried hundreds of times on a server; however, to catch somebody that tries to connect to 50 different servers in the domain but only succeeds once is not a very easy thing for a human to catch, but it is very easy for the system to identify.
IoT Botnet Detection
Internet of Things devices are very often deployed on the network as trusted assets, which by itself is a problem. We should flip that model on its head. These types of devices are purpose-built. They have a very narrow set of communications. This makes them very easy to baseline and alert on deviations.
Market Guidance
Every vendor is telling you how machine learning and artificial intelligence is making their platforms better and you more secure. It is important that we take a step back and unwrap the story. There are certainly components that will deliver value, but there is also a lot today that sounds great and yet the reality of what it’s going to do for you today may be less so.
Narrow the scope of what you’ll look for and look at it from a dataset. This will help you reduce the number of false positives. The value of this idea of machine learning, and eventually artificial intelligence, is that it’s supposed to make it easier for the analysts to do their job. It is supposed to reduce the number of false positives so that you are only acting on things that are important or real. If you take too broad of an approach, you end up with the inverse problem.
It’s actually going to make your life harder because it will give you false positives for all kinds of things that are normally happening on your network, like the addition of new devices, the addition of new applications, the patching of a server, or the new operating system that you downloaded to your devices. These things are all going to look like deviations from normal behavior, and it’s going to make life harder, not easier.
You want to consolidate as much data as you can. Create a data lake approach. Bring data in from lots of different places and apply machine learning to that narrower set of data. Again, you don’t want to apply machine learning to the broad set of data, but you want to look at it from a cross-platform perspective.
Machine learning and artificial intelligence are at the top of the hype cycle, and they will not replace your cybersecurity team. Ultimately, use caution when evaluating and deploy strategically.
To take advantage of some of the real-world machine learning algorithms available with network traffic analytics, download Scrutinizer today.
