
Often I find that there is overlap in the type of insight sought after in syslogs and NetFlow tools that the security and network teams want to see. It causes confusion, and even the need to review each other’s tools, searching for the data they are missing within their own. This is why understanding how to use a UDP forwarder or syslog forwarder in your environment can increase the efficiency of your network.
How It All Works
A syslog forwarder is designed to receive system logs and send the data to the appropriate system much like a UDP forwarder, which forwards UDP packets to multiple devices. Upon receiving data, the UDP forwarder duplicates the UDP data (e.g. syslogs, NetFlow, IPFIX, etc.) and forward the information to your designated forensic investigative system.
Plixer’s Replicator follows a similar process by listening on designated ports. Once UDP data is collected, the Replicator will make duplicates of the data. From there the Replicator will replace the original destination IP address without changing the original source IP address.
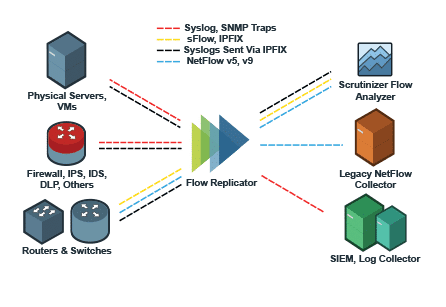
Here is a diagram of how a forwarder fits into a network. We can track the behavior of a UDP forwarder like the Replicator. The devices on this network all have our Replicator set as their destination IP address. Upon arrival of the UDP datagram, the Replicator makes quick work of duplicating and sorting the data it has received. It then forwards the data to the configured destination IP address(es) and port(s) that the collection solutions are listening on. This is all done while leaving the original source IP address intact, which means the syslog forwarder/UDP forwarder stays completely transparent to the collector.
This process is important when you are forwarding UDP data to multiple systems that monitor network traffic as it ensures that each collector believes that they are receiving the data from the original source.
Added Security
When you think of UDP forwarding, added security doesn’t normally come to mind, but this is something worth noting. Think about it. After a hacker gains access into your network, surely they’ll know what traffic to hide. Maybe they’ll even be able to hide their traffic from a couple tools, but will they be able to hide their logs and traffic patterns once they have been replicated to multiple tools? Doubtful.
Scale For Capacity
While a UDP Fanout may make things more difficult on intruders, a flow Replicator continues to ease the stress of large networks by allowing the user to scale for capacity. Larger networks that experience higher log volumes, can use Replicators to balance the load. Similarly, a UDP forwarder/Replicator can reduce stress on routers and switches across your network.
The health of the forwarding process can be tracked in the dashboard. From here we can monitor the amount of traffic coming into the network. We can create profiles for new collection systems by specifying the ports they will be listening on, and the Replicator can even alert you when a collector is down.
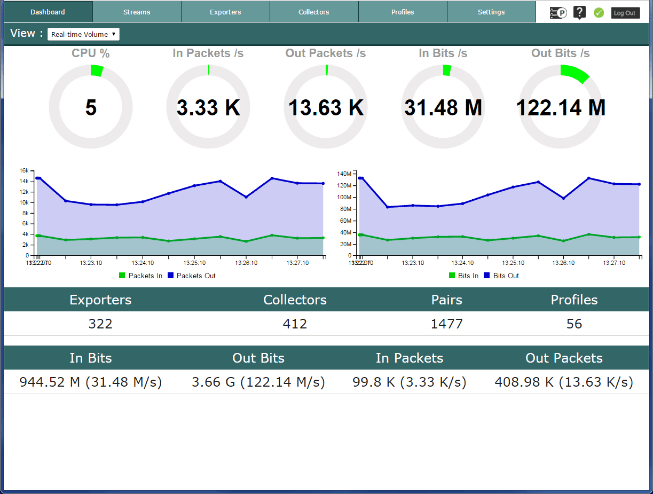
You can use a couple different views to monitor traffic coming across the Replicator. I found the new favorite to be the Sankey graph below because it gives a quick view of your networks topology.
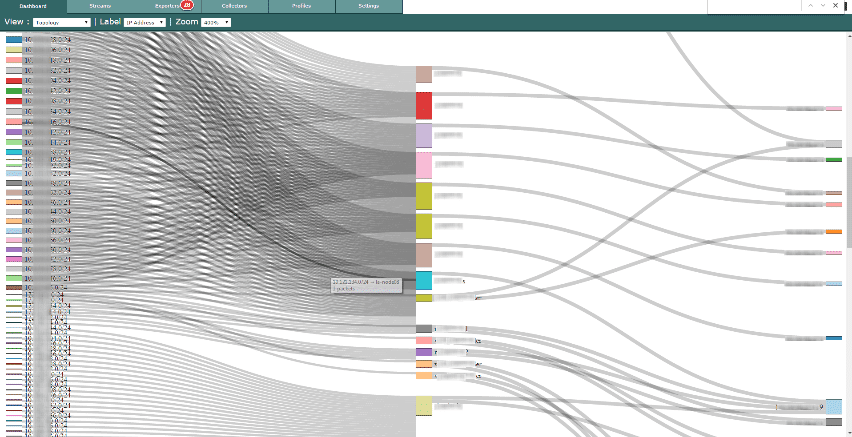
The Replicator can be used in any environment with more than one team or one tool. It’s an easy step to simplifying your network and reducing stress on devices. If you’d like to explore the benefits of the Replicator on your own network, you can test the Replicator here.
