
Questions regarding deduplicated NetFlow often come up when beginning to research NetFlow solutions. This blog will address some of the reasons why deduplication might not be the best way to go.
What is flow/data deduplication?
Data deduplication, simply put, is a technique for eliminating duplicate copies of repeating data. In terms of NetFlow collection, deduplication of flow data is the process of aggregating/combining flows that traverse multiple network devices into a single flow.
NetFlow deduplication is performed when multiple routers/switches export the same flows for two hosts communicating with one another.
If a flow (e.g. A to B) with a matching tuple is collected by three routers, the collector will save only one instance of the flow. This single flow is usually focused on the standard tuple, with few additional details. Elements not included in the standard tuple, e.g. details like DSCP or next hop, are either dropped or their values assumed.
Because the process of deduplication results in lost details, the original flows are in many cases saved as well. Therefore, the belief that flow deduplication saves disk space is false—unless of course you are willing to work without much of the rich details that make NetFlow and IPFIX awesome. In truth, NetFlow deduplication often leads to greater disk space consumption.
Before I go any further, let me take a minute to refresh our knowledge about flow technologies, ingress and egress metering, and then discuss how deduplicated traffic might be an issue.
Most NetFlow or IPFIX implementations are unidirectional, meaning TCP connections between two hosts results in two flows (i.e. A to B and B to A).
The accuracy of your results after deduplication depends upon whether you’re doing ingress, egress, or both ingress and egress monitoring.
Many vendors in the flow technology space will tell you that de-duplication is the only way to collect and report on NetFlow. Here is one way that a particular vendor tries to solve for duplicated NetFlow.
Deduplication, as we are learning, is the process of taking a flow that traversed two or more routers and saving it as a single flow, with a reference to the routers, switches, or firewalls the flow traversed. Because multiple flows are involved with TCP connections, the total packet and byte counts are averaged when creating the new single, deduplicated flow. Not good if the goal is to show actual traffic statistics.
Vendors will also have you believe that by de-duplicating the flows, they will save on the disk space needed to store and save historical data.
The truth is that in most cases, the vendor not only stores deduplicated flow records, but also stores the original records. Therefore, they are actually using more disk space, not less.
Many times, the collector drops flows when routes are asymmetrical. This is because there is not a direct return flow that matches the initiating flow.
Dropping flows is never a good thing!
The solution to NetFlow deduplication is to save 100% of the data and be able to search on 100% of it within seconds across all of the distributed flow collectors. Loaded with all the data related to the search, you can trace the flow in both directions. This means deduplication and stitching is performed as needed.
Let me show you some ways to view a flow that traversed multiple hops in your network.
The report below focuses on a single conversation that moved across multiple points on the network. Notice that there are a number of individual connections in this, where my workstation is the destination host.
For this exercise, I focused on a secure web (https – 443) connection going from source host 13.107.18.11 to my workstation (sa45jtc72scottr.plxr.local), using ephemeral port 10656. From this report, I have learned that the connection did take place. But how much traffic did the connection generate? This report is showing 1.016GB of traffic, which is the sum of the traffic occurring on all hops in the flow.
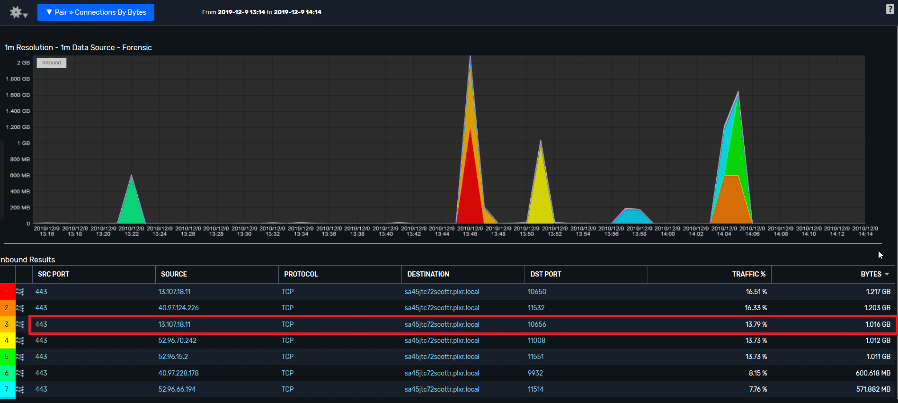
This report shows the connections presented using duplicated flow records collected from all devices in the conversations network path.
If I add an interface reference to the report, the connections are deduplicated, and I have a reference to the exporters and the input and output interfaces on those exporters.
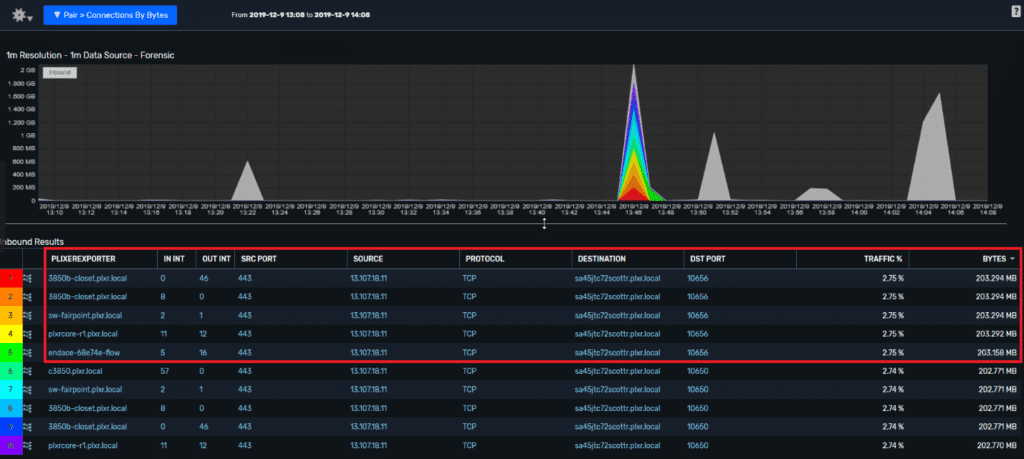
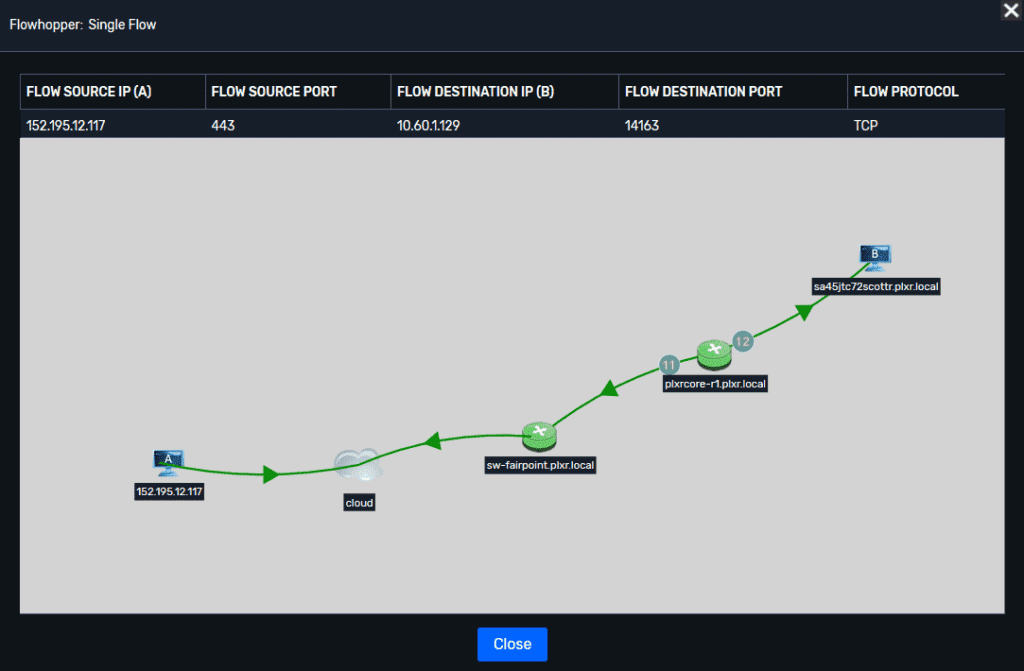
If you click on the icon to the left of any connection, you can visually display the full path.
Final thoughts on deduplicated NetFlow
NetFlow and IPFIX reporting is a balance between pre-processing data and processing on the fly. Deduplicating every flow received down to a simple tuple may have made sense in a NetFlow v5 world, but today we live in a world of Flexible NetFlow and IPFIX.
That means the old simple flow tuple is a tiny part of the data we can expect to collect and report on. Using critical processing power to distill data down into an obsolete construct is simply a waste of time and resources, and results in lost critical information.
Security and network professionals need access to the right data at the right time to meet the needs of a digital business. Have you ever found that you are missing critical data when investigating particular network issues? Contact us, we can show you how to collect and report on everything.