Do you need to search for a single IP address across trillions of flows? The ideal system for enterprise NetFlow collection should allow you to simply type in an IP address and within 2-3 seconds, it should serve up the results being sought after.
Collect Billions of Flows per Day
Even when tens of thousands of exporters are sending billions of flows per day (i.e. trillions of flows per year), the ideal querying system will find the matching data across distributed flow collectors in just a few seconds. An example is given below.
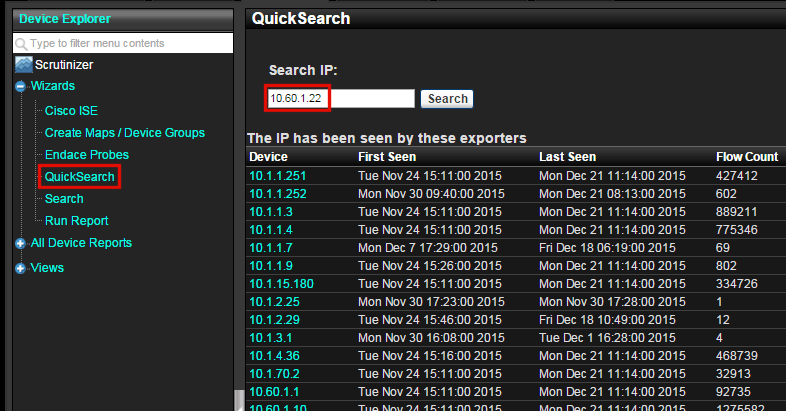
Notice in the above that all of the exporters that saw flows from the device (10.60.1.22) being searched on are listed. Just drill in to obtain rich NetFlow and IPFIX details such as those from Cisco AVC or nvzFlow. Below is a report of the host being searched on.
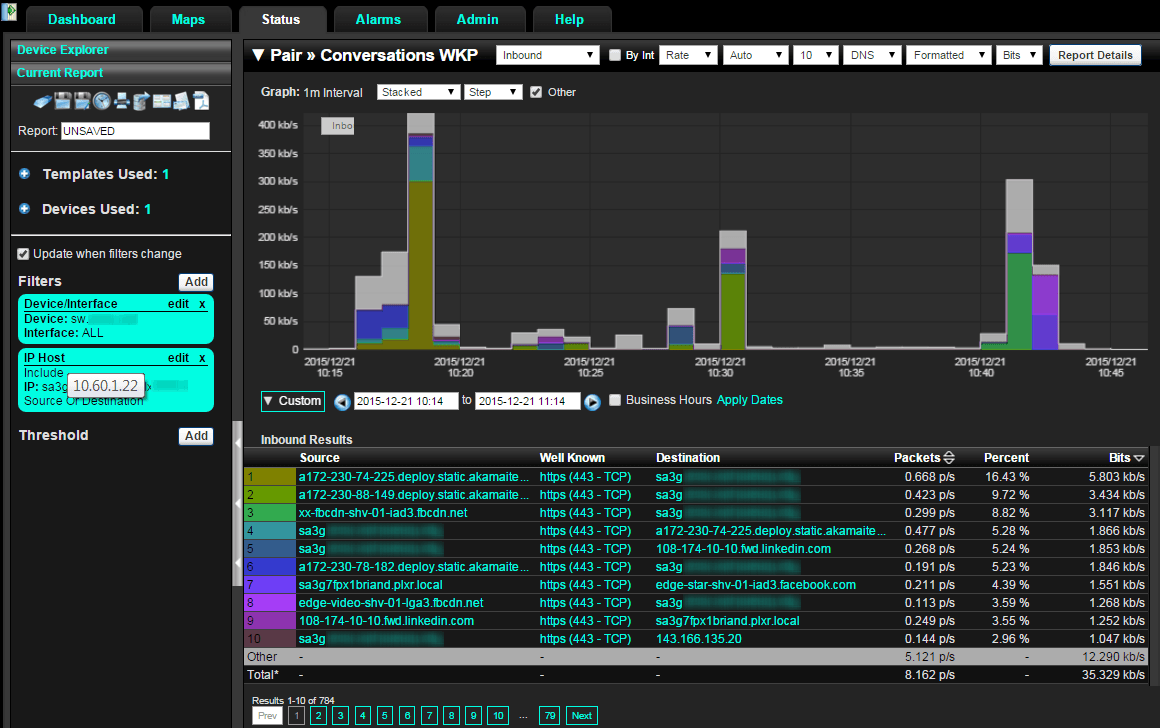
Big Flow Data
The problem that most flow collection systems struggle with when it comes to big flow data is two fold:
- Collection rates: With more and more vendors exporting NetFlow or more likely IPFIX, flow volumes are increasing. The reason vendors are choosing IPFIX is because it is the official Internet standard for all flow technologies. It allows the vendor to export unique values including variable length strings. Details such as jitter, packet loss, codec, caller ID are all being exported by Cisco, SonicWALL, FlowPro APM and others to enhance the traffic insight into VoIP traffic. For TCP connections we have seen details on TCP window size, retransmitted packets, packet size distribution, round trip time, client IP, server IP, URI, URL and much more. Popularity of the protocol is growing and with it, the size of the flows is widening. This places greater demands on the collector vendors to support and report on the new details – quickly. Most vendors simply don’t keep up with new reports and before that even becomes a problem, there is another issue. Often times customers learn that the legacy collection architecture can’t keep up with the sheer volume of flows the existing infrastructure can generate.
- Database size: Even when vendors can keep up with the flows generated, being able to regurgitate the data on demand in a reasonable time frame such as under 5 seconds can be huge obstacle. When database tables get big, queries take longer to run, the server bogs down and the user becomes frustrated.
Governments, service providers, large universities and massive enterprises depend on our NetFlow and IPFIX distributed collection system to quickly deliver the details necessary when end points are under attack. The IT teams at our customer sites leverage our network incident response system on a daily basis to investigate application performance issues as well. Solve your big flow data problem with Scrutinizer.